Python
Step 1:
Used Beautiful Soup for web scrapping to extract data from MoMA’s exhibition history website, focusing on the period from 1990 to 2024. Merged this web-scrapped data with MoMA’s Open Exhibition Index Data file covering 1929 to 1989, creating a unified CSV file dataset.
Step 2:
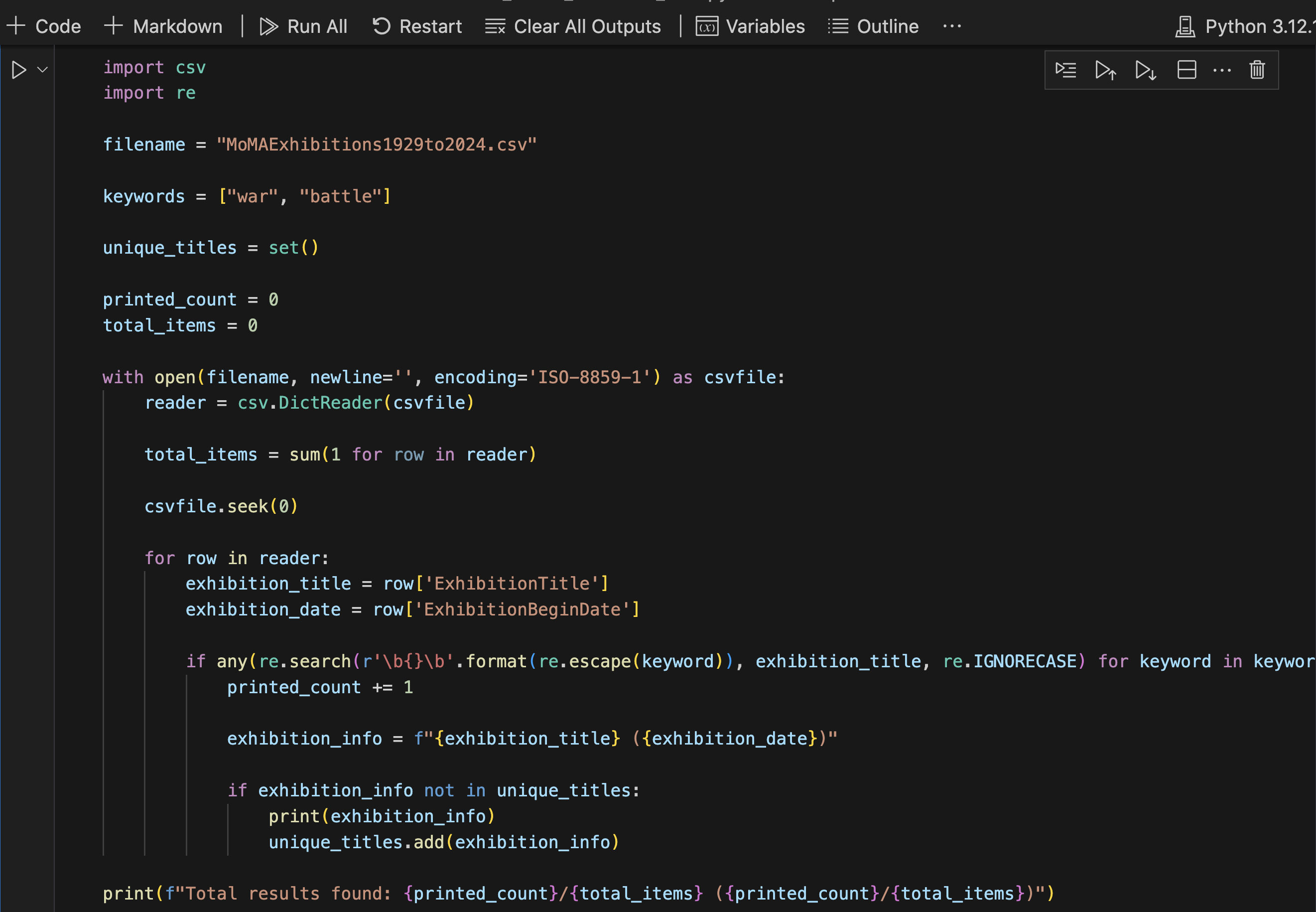
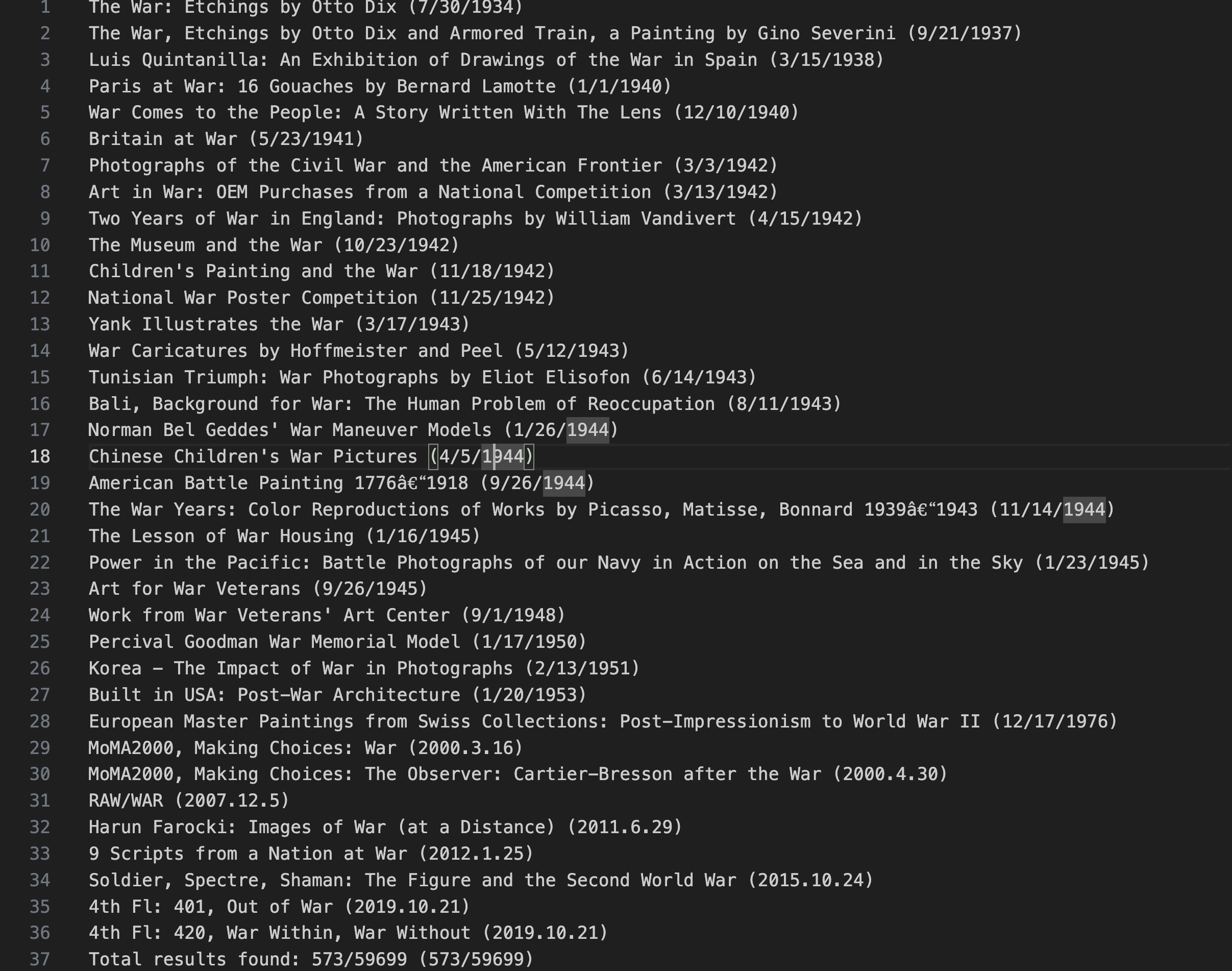
Implemented a Python script to iterate through the exhibition history dataset containing 5,457 items, filtered for exhibitions with titles containing "War" or "Battle". Ensured the printed output is refined, excluding redundant or irrelevant results (e.g., "Andy Warhol").
Step 3:
From a pool of 5,457 items, total of 36 exhibition items were printed. Out of these, 20 selected exhibition items were meticulously cataloged using Omeka-S, an open-source web-publishing platform to create a public digital exhibition. 20 items were bulk-uploaded as a csv file, that was created by python script.
Step 4:
Each item underwent a thorough cataloging process adhering to metadata standards like the Dublin Core Standard and CIDOC CRM Ontology. Also controlled vocabulary such as wikidata Q number and Getty ULAN was used. A dedicated digital exhibition website has been launched to showcase the curated collection.
For python script, please visit my Github page